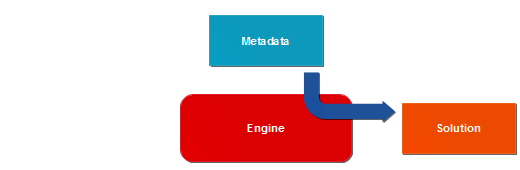
We use the term "metadata-driven" to describe IT solutions in which functionality is defined in data. Taking this to the extreme can provide unparalleled levels of speed, simplicity and versatility.
In a metadata-driven solution, metadata is interpreted by an engine to form part of the solution.
The main advantage of this is development ease and speed. Functionality that is provide by the combination of metadata and engine can be created very quickly, without further programming.
There are lots of examples of this. For example, in an a database system, the data definition is the metadata. It is interpreted by a database engine to produce the data structures that form the solution.
Metadata-driven systems are very powerful. But what if we took it further? What happens if the metadata itself is defined by another set of data, but processed by the same engine? Lets distinguish these as primary and secondary metadata.
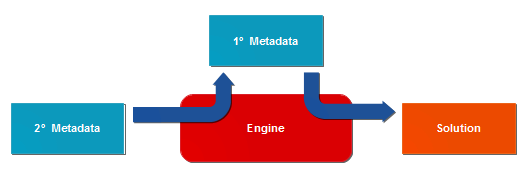
In this arrangement, the secondary metadata for a database system defines how to maintain the data definition (primary metadata), which in turn defines the data for the solution. The secondary metadata defines the type of solution. In a similar way, you could have secondary metadata to define, say, a content management system, or a work flow engine.
Using the same engine for processing primary and secondary metadata means that different solution types, such as databases, content management, and work flow, are dealt with in the same way. Where otherwise these might use very different concepts and tools, a single engine unifies them allowing the same concepts and tools to be used to develop different types of solution.
To use the same engine, you also need to unify the data structures. The solution data, primary metadata and secondary metadata require a versatile data store, such as a triple store, that can achieve this.
Now we have a versatile engine, versatile data store and two layers of metadata. What happens if we add another layer?
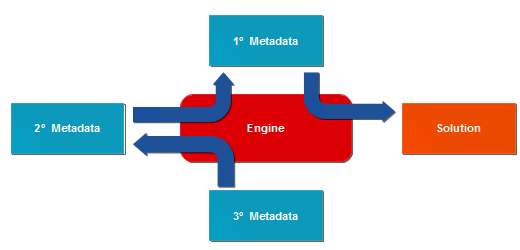
Now the different types of solution are themselves defined in metadata.
This provides massive versatility, a real "do anything" solution. Like a series of magical levers, you use tertiary metadata to define the type of solution, secondary metadata to define how the solution is parameterised, and primary metadata to define the solution. As well as being versatile in itself, this lets you mix different sorts of applications. Want to mix content into your database application? No problem. Want a finance application with work flow? No problem. Want something nobody's imagined before? No problem.
In reality, the distinction between solution data and metadata breaks down. You have layers of definition: the top is the user solution, then layers of metadata, with self-defining metadata at the bottom. This is a whole new way of building solutions, with limitless possibilities.
This is the approach we use inside the Metrici platform. It uses layers of metadata and a flexible data store, which makes it fast to develop, consistent across different application types, and able to tackle any sort of development.
Having worked with this approach, I get frustrated with other ways of building solutions. Nothing else can match it for speed, power and simplicity. It makes me think that, one day, all software will be built like this.